
Three organisations. Five teams. Seven Hours. What tools can they create to solve key challenges facing galleries, libraries, archives and museums?
Intro
At Numiko, we're always looking for ways to push the boundaries of what's possible with digital experiences. Our recent hack day gave us the perfect opportunity to do just that.
This ‘Hackathon’ is the first of these quarterly events, where we bring our team together alongside important partners to get stuck into interesting problems faced by our clients.
Over the course of the hack day our five teams, each with a different problem statement, took their ideas from the drawing board to working prototypes. These simple prototypes didn’t need to be polished, they just needed to show they could work to solve a user's need and demonstrate the potential of the solution proposed.
For this hack day, we focused on the GLAM (Galleries, Libraries, Archives and Museums) sector. We were joined by members of the Knowledge Integration team, who brought their expertise in synchronizing data between back-office systems for a wide range of archives and collections. We were also joined by Trusti, providers of certificate authority and immutable ledger architecture, whose ability to provide cryptographically secure and publicly verifiable tokens has great potential to help with verifying collection records.
The Challenges
On the day we split into five teams, and each focused on solving a different challenge for the GLAM sector. The challenges tackled were:
- Verifying collection records
- Creating 3D models for 2D assets
- Uncovering ‘hidden gems’ in collections
- Generative UI for collection interfaces
- Automatic topic pages
These address areas where we’ve identified potential opportunities for new tech to solve problems facing digital collections. The hack day gave us the perfect opportunity to rapidly build prototypes to see if we could develop solutions to these challenges. The teams only had a few hours, but they all came up with great ideas and created some really interesting prototypes that will help inform how we approach digital collections in future.
Verifying Collection Records
Team One’s problem statement was ‘museums and collections need a way to prove digital assets are real and not forged’. Institutions lending or borrowing items for exhibitions need to be able to verify that the objects are real and, at the moment, this results in a time-consuming and laborious process for handling lending and borrowing. From 2010 to 2019 the National Gallery spent between 16 and 22 days a year entering data for exhibition loans.
Team One’s proposed solution to this problem was to develop a centralised and secure framework that captures the dialogue and decisions involved in the lend/borrow process. This framework would streamline the exchange of information, reduce redundant data entry, and enhance security. This team was joined by Andrew from Trusti, who could bring their expertise on digital verification systems.
The team used Postman to create and test API calls to Trusti, ensuring that the communication between institutions could be securely managed through the API. A Python script was crafted to automate the creation and management of loan journals. This script demonstrated how institutions could handle the entire process—from initial request to final approval—within a centralised system.
This team’s solution was inevitably focused on back-end code, so it can’t be showcased visually. But their plan for a centralised, secure framework for managing exhibition loans addressed a serious pain point for the GLAM sector. In just a few hours the team planned and prototyped a practical solution that could make collection loans more efficient and secure.
Creating 3D models from 2D objects
Team Two addressed a very different challenge. Their problem statement was that 3D scans of objects are scarce and expensive to create. 3D models can be a great way to present objects in digital collections, but the time and resources required to produce them often mean only a few items in a collection have 3D assets to display.
The team thought that AI could provide an opportunity to automatically generate 3D models from static images already available in the collection, without requiring any new photography. They reviewed a range of photogrammetry and AI tools and found that some AI tools for converting images to 3D models could be extremely effective. Using the Royal Armouries website to demonstrate the tool in action, they showed how 2D objects in a collection could be transformed into 3D models users could interact with.
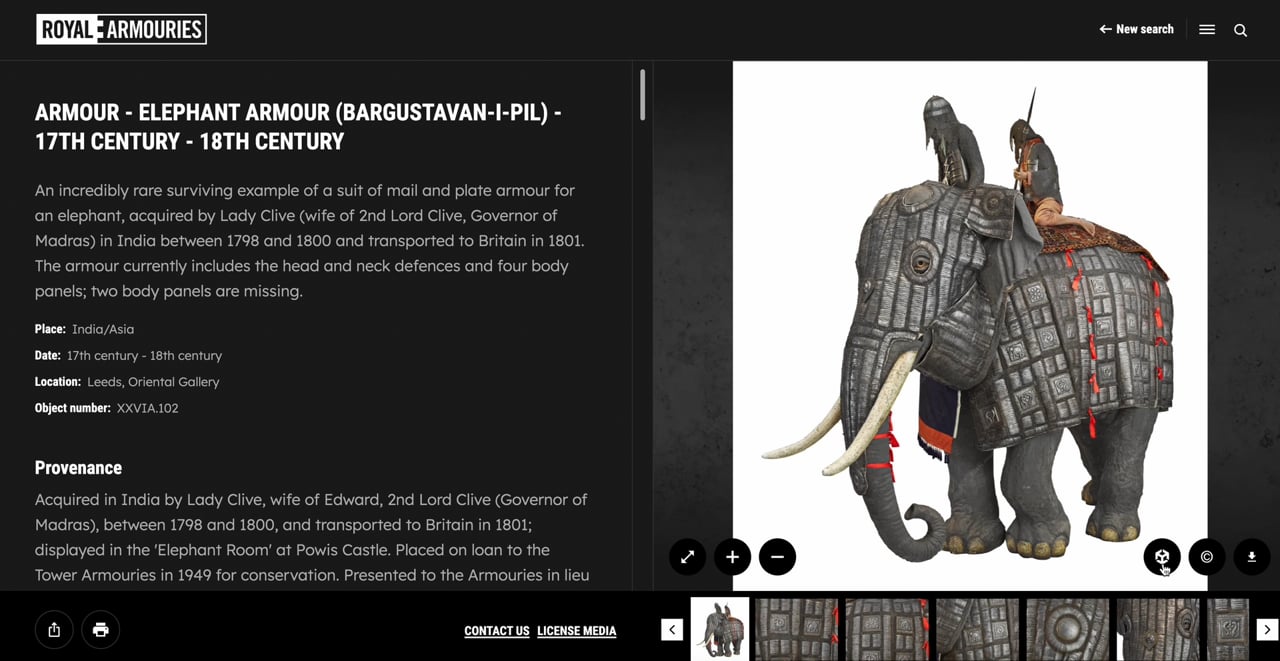
They also investigated the possibilities of augmented reality (AR) interactions, virtually projecting the 3D models into a space using a mobile device made them far more engaging.
The team’s prototype showed the exciting possibilities of this technology for digital collections. Going forward, we’d like to explore how we could scale this up by using an API to generate the models and integrate this with the collections management system.

Uncovering hidden gems
Museum collections can be vast, containing many thousands of objects. This can be daunting to users, and as a result, usually only a very small percentage of objects in a collection are ever seen by the public. We wanted to create a way for users to more effectively interact with ‘the other 99%’ of a collection that is not displayed in a museum.
To help uncover these rarely seen objects, Team Three developed a Related Items Engine using PostgreSQL and embeddings to find links between items with the help of OpenAI.
The team’s prototype shows a range of ‘undiscovered’ objects that have rarely, if ever, been viewed by users. The user is invited to select three objects, and then the tool uses AI to establish links between them using the metadata available, highlighting similarities and crafting a narrative that provides useful context for the objects. The interface would be ‘gamified’ to encourage users to discover new connections between objects, rewarding users with badges for linking objects that have not yet been combined by anyone.
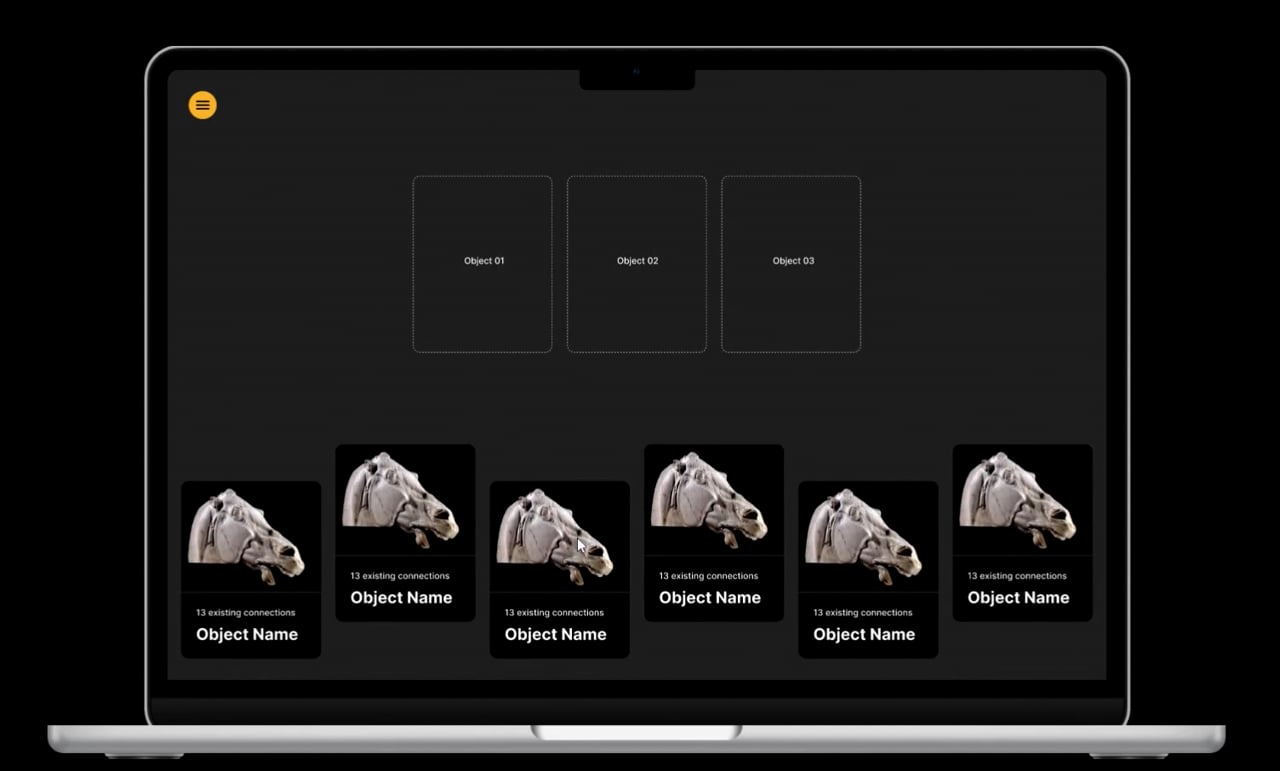
This tool could help users dig deeper into digital collections, employing gamification to encourage users to uncover ‘hidden’ items in a collection that are usually kept behind the scenes.
Generative UI for collection interfaces
Team Four looked at the potential for tailoring collection interfaces to different user’s needs. Their problem statement was “Collections are accessed by a wide range of users with different needs and levels of expertise. Can we create a single interface that generatively adapts to them?”.
They approached this by considering how they could remove complexity from a user interface whilst encouraging exploration. The team felt that collections interfaces don’t often present onward journeys that are anchored to the user's original journey, meaning a user must go ‘back to the start’ to search the interface again. They proposed building a collection interface based on the principle of ‘never go backwards’, meaning that the user experience always builds on the last query, but keeps the original context.
Their prototype envisaged an extremely simple and easy-to-use UI driven by AI, whereby a user can enter queries that are answered with a curated range of objects related to their query and the context around them using AI. The team’s prototype revolved around a few key components: A React-based user interface for a dynamic, responsive experience, a Large Language Model (LLM) using OpenAI to understand user queries and generate relevant responses, and an Elastic Search index to efficiently search and retrieve collection objects.
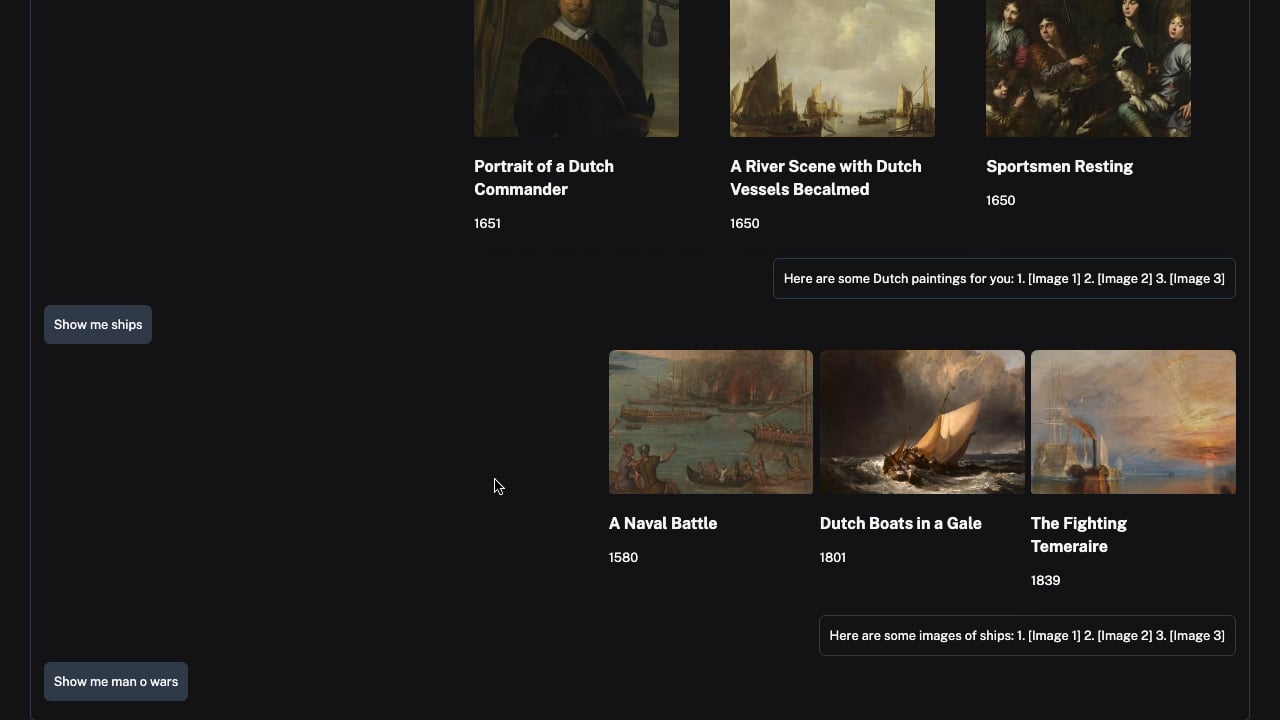
Users would be presented with an ‘infinite’ scrolling UI, allowing them to have a dialogue with the collection. The simplicity of the UI makes it suitable for all users, and by using an AI curator to tailor content, it can effectively serve users with different backgrounds or levels of understanding. We’re looking forward to developing this concept further, and potentially implementing it in future projects.
Automatic topic pages
Collection CMS users don’t have time to create enough topic pages for large collections, and in many collections, the topic pages that do exist are often very dry and unengaging. Team five were given the challenge of making topic pages more detailed and compelling, whilst reducing the content burden on the web team.
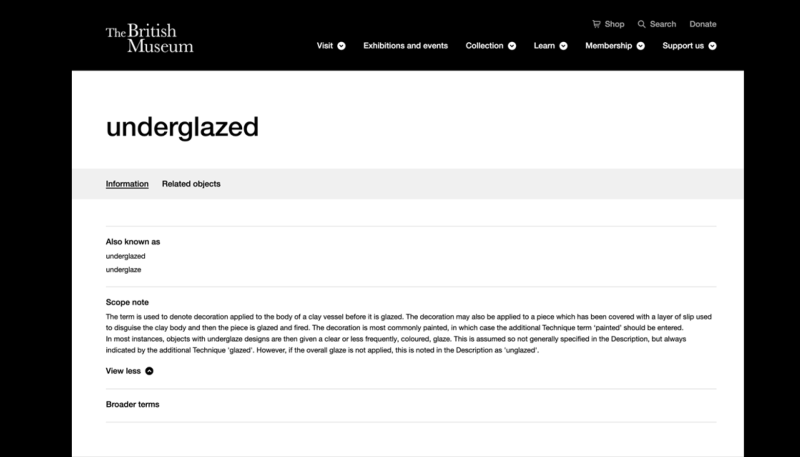
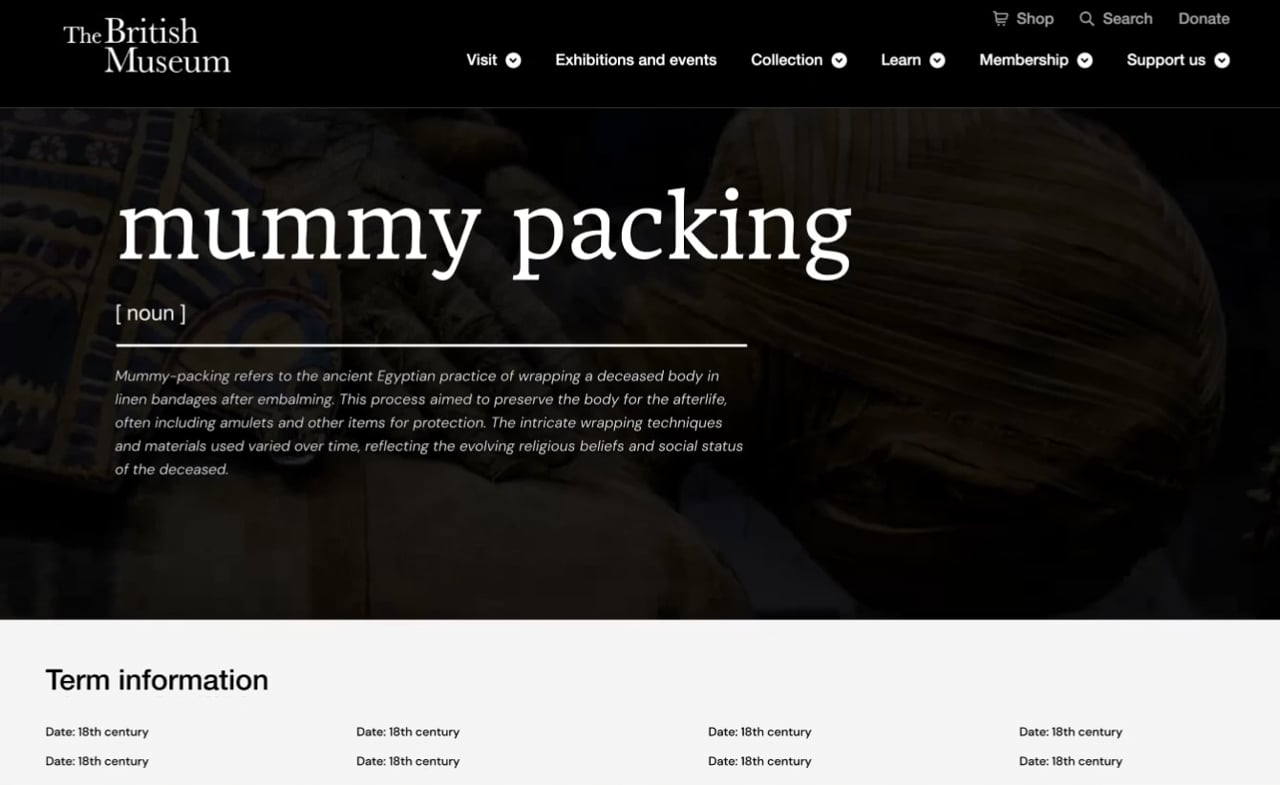
The team looked specifically at the British Museum’s collection to give their project a real-world footing. They focused on ‘term pages’, a type of topic page used to collate objects tagged with that specific term.
Existing term pages (see below) on the current British Museum website often lack definitions. With so many different term pages, it would be a huge content effort to add all of these in manually.
The team designed wireframes for a new UI for term pages, consolidating the information and related objects tabs, and adding a new ‘related articles’ section. Because the term description field is often missing for many term pages, the team used AI to automatically create term descriptions whenever the field was left blank.
The resulting prototype page design (shown below) is far richer and more engaging than the previous term page designs, with more relevant content being surfaced.
The team also built a proof-of-concept demonstration with AI to create the term descriptions whenever they were blank, using the drupal.org OpenAI model to interface with ChatGPT and insert an AI-generated description.
It’s these ‘nitty-gritty’ changes to elements like term pages that add up to making digital collections more usable and explorable. Although only an early prototype, we’re excited by how much we were able to improve term pages in so little time.
The hackathon experience
The purpose of a hackathon isn’t just to generate interesting ideas for new tech and generate a bunch of exciting prototypes we might be able to iterate on in future. It’s also to excite the team and get them learning about new tech and projects that they might not otherwise be familiar with. We had some great feedback from the teams about how they found the day and what they learnt. Here’s a few snippets of what they had to say:
“It was a great bonding experience and I feel the solution we came out with could easily be added into the project as a starting point to grow a bigger solution.”
“The day made me excited to work on similar tasks in the future.”
“A really great team building exercise and such a joy to work on something for us”
It was also interesting to reflect on how many of the potential solutions our teams arrived at and prototyped involved deploying AI tools. The potential AI offers for the GLAM sector is something we’ve written & spoken extensively about, and it was great to start taking some of these ideas from the drawing board to the prototype stage. If you work with digital collections and find that some of these problems resonate with you, get in touch, we’d love to talk.